

新智元报说念
剪辑:桃子 LRS
【新智元导读】哈佛斯坦福MIT等机构初次提倡「精度感知」scaling law,揭示了精度、参数规模、数据量之间的融合关系。数据量增多,模子对量化精度条款随之提高,这预示着AI规模低精度加快的时期行将收尾!
就连「量化」也不管用,scaling law简直要闭幕了吗?
一提scaling law,东说念主们要点热心的是参数规模、数据量等身分,却冷漠了「精度」这一关键变量。
哈佛斯坦福MIT等机构接头东说念主员竟发现,低精度锤真金不怕火会缩小模子的「有用参数目」!
对此,他们提倡了「精度感知(precision-aware)」scaling law。

论文地址:https://arxiv.org/pdf/2411.04330
对于推理过程来说,锤真金不怕火数据越多,量化带来的性能耗费越大。
就锤真金不怕火来说,「精度感知」scaling law粗略瞻望不同部分经受不同精度的模子的耗费。在某些情况下,用低精度锤真金不怕火LLM可能更有用率。
论文中,作家融合了锤真金不怕火后和预锤真金不怕火量化的scaling law,开垦了一个完整的表面框架。
这个单一函数格式不错瞻望在不同精度下进行锤真金不怕火和推理时的性能左迁。
基于465次以上的预锤真金不怕火实验,在最大1.7B参数,锤真金不怕火数据量达到26B token的模子上考证了最新的瞻望。

艾伦接头所科学家Tim Dettmers对此评价说念,这是很万古刻以来,最弥留的一篇论文。它以强有劲的凭据标明咱们正在接近「量化」的极限。
「论文径直指出:锤真金不怕火所需的token越多,所需的精度就越高,这对通盘规模和GPU的改日王人有粗豪的影响」。
就连AI大牛Karpathy也转发了这个帖子。
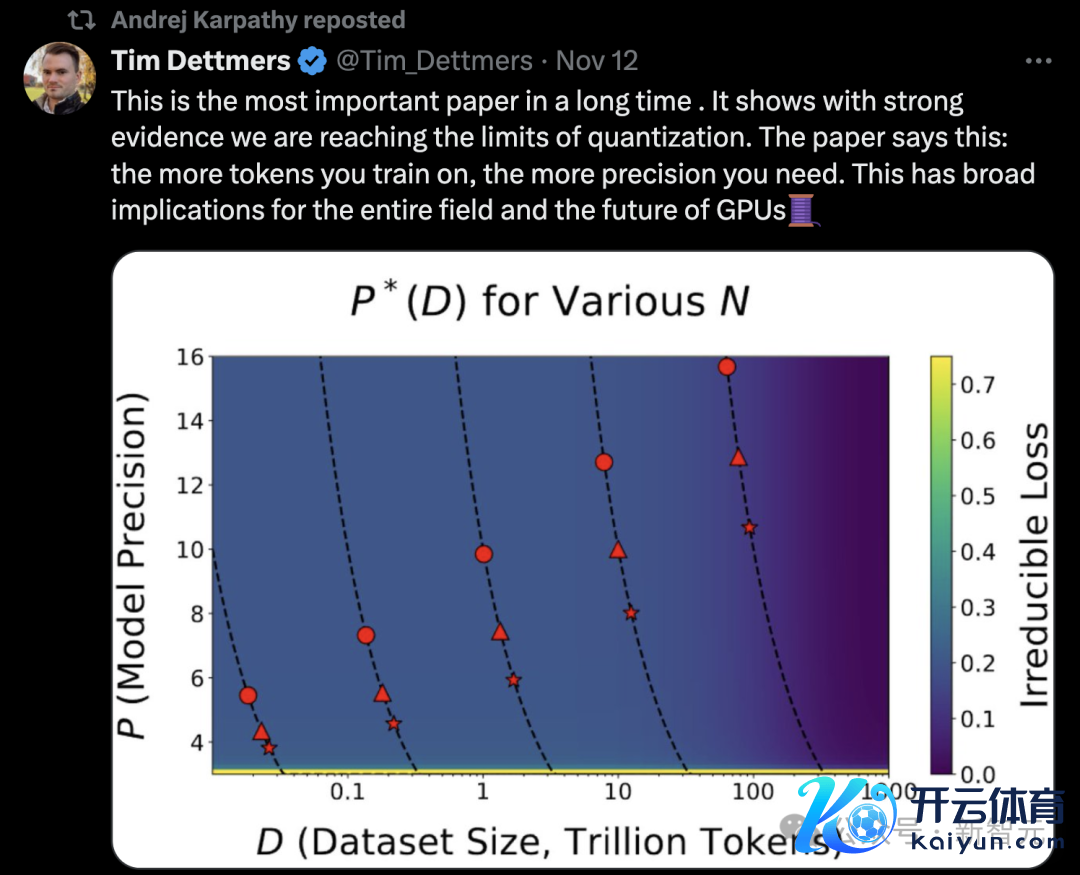
图中不错看到,对于20Btoken锤真金不怕火,8B模子在16位精度下更有用,70B模子,8位仍然可行,但效劳如故入手缩小。注:8B模子(圆形)、70B模子(三角形)、405B模子(星形)
OpenAI接头员Clive Chan示意,拥抱scaling law,望望起先进的量化有贪图(mxfp,Pw≠Pkv≠Pa等)怎样推动前沿将会很酷好。另外,我个东说念主以为,值得破耗一半的计较预算来进行一次大规模运行,以考证这个拟合是否适用于大模子。

不错说,AI规模的大多量进展,王人来自计较才智的进步,这主要依赖于低精度加快(从32位到16位再到8位)。
但这种趋势目下正接近尾声。
加上物理拒绝,这援手了scale闭幕的「好意思满风暴」。
LLM正接近「量化」scale极限
不消置疑,scale早已成为业界公认的深度学习中枢驱能源。
2020年OpenAI团队,以及2022年DeepMind团队在scaling law的论文中,接头了模子/数据集大小之间的量度,以均衡性能和计较。

关系词,模子锤真金不怕火和推理时使用的精度,是影响本钱和性能的弥留「第三身分」。
深度学习正在向低精度发展:面前的前沿模子(如Llama-3)使用BF16锤真金不怕火,何况普遍悉力将预锤真金不怕火范式转向FP8。
下一代硬件将撑执FP4,而仅权分量化的进展已导致大规模二进制和三进制锤真金不怕火。
这些范式能走多远?
具体来说,论文作家提倡了以下问题:
精度、参数、数据三者之间怎样量度? 它们在预锤真金不怕火和推理阶段各有什么区别?

其实,接头精度scaling具有挑战性,因为scaling law的接头以前旨在放手细节性的完毕细节,追求普遍的函数格式,而量化接头以前相背,专注于细节:怎样进行量化,使用什么类型,应用于模子的哪些部分。
为了完毕这少量,接头东说念主员商量了多样合理的函数格式,并采纳了一个将量化实施细节与耗费scaling「分手」的格式,由此粗略在许多骨子情况下瞻望耗费scaling。
总的来说,作家接头了在锤真金不怕火期间和之后,跟着数据和参数的变化,精度对耗费的影响怎样推广。
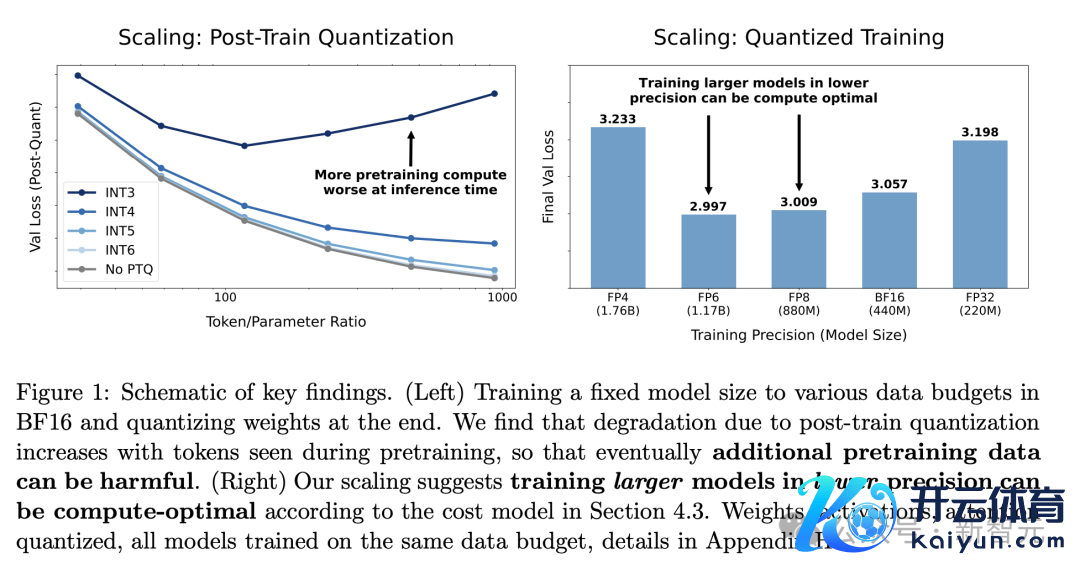
接头发现了,在后锤真金不怕火量化的影响:量化导致的性能左迁,随数据量增多而增多。对于固定模子,最初某个点后不息锤真金不怕火可能无益,这种影响在模子后期量化时极度融会。
针对预锤真金不怕火精度的最优采纳,计较最优的预锤真金不怕火精度,以前寂然于计较预算,但当模子大小受限时,这种寂然性不再设立。在这种情况下,最优精度随计较量渐渐增长。
对于N个参数的言语模子,在D个token上进行锤真金不怕火,锤真金不怕火精度为P_train ,锤真金不怕火后权重精度为 P_post ,最终接头东说念主员找到了一个融合的scaling law:

其中,A、B、E、α、β是正拟合常数,δ_PTQ是指推理前锤真金不怕火后量化引起的耗费退化
Tim Dettmers在长文中示意,英伟达Blackwell将通过硬件层面完毕的块级量化来提供出色的8位计较才智。这将使8位锤真金不怕火变得像从FP16切换到BF16相同爽脆。
关系词,从这篇论文不错看出,改日还需要最初8位的精度来锤真金不怕火许多模子。
相较于其他模子,运行Llama 405B进行推理是一个广宽的挑战。但论文标明,中等参数规模模子(如70B)也难以在低精度下高效锤真金不怕火。
从Dettmers的个东说念主警告(许多失败的接头)来看,你无法讹诈效劳。
要是量化失败,那么零散化也会失败,其他效劳进步机制亦然如斯。要是这是简直,咱们目下已接近最优解。在这种情况下,他只看到三条前进的说念路...
(1) scaling数据中心:这还能不息scaling约2年。
(2) 动态scaling:转向更小的专科化模子或更大/更小的模子。
(3) 学问蒸馏:蒸馏的行为与其他技艺不同,可能具有不同的特色。
通盘这些意味着范式将很快从「scaling」转向「怎样讹诈现存资源」。Dettmers以为「怎样匡助东说念主们通过AI提高坐褥力」这种念念维面孔是最好的前进标的。这种念念维面孔更热心经由和东说念主,而不是技艺自己。
锤真金不怕火后量化Scaling Law
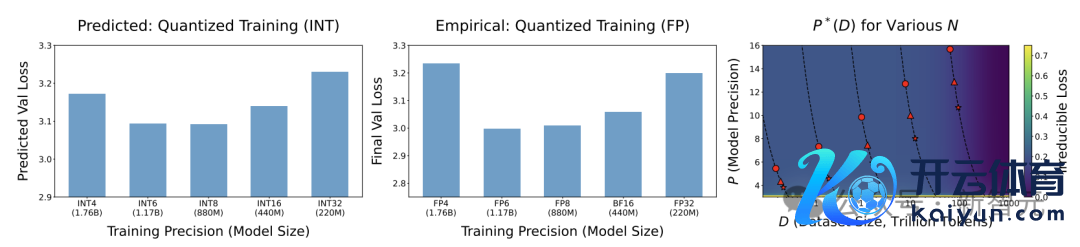
最爽脆,亦然最常见的量化技艺即是将现成的模子进行锤真金不怕火后量化解决(post-train quantize)。
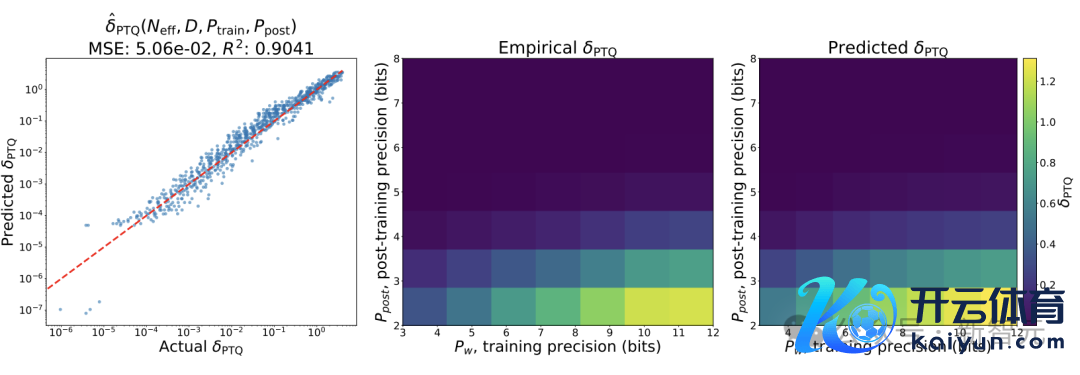
接头东说念主员滥觞使用BF16格式锤真金不怕火的模子,并经受GPTQ技艺来进行锤真金不怕火后的量化解决,拒绝发现锤真金不怕火后的量化在数据推广性方面发达欠安。
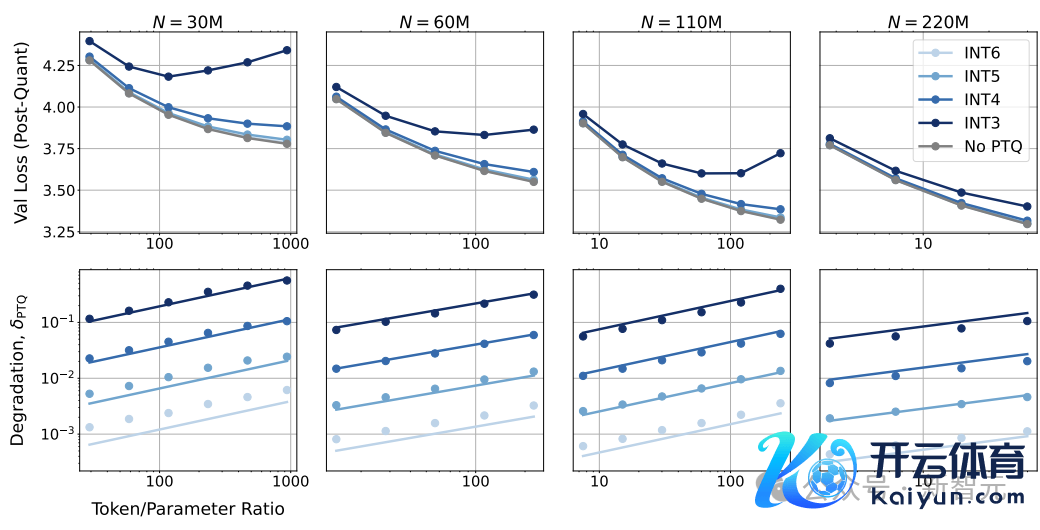
模子在锤真金不怕火后量化以及与锤真金不怕火收尾时比较,出现了性能退化。
不错发现,跟着锤真金不怕火数据量的增多,通盘尺寸模子的性能退化δPTQ王人在增多;但对于固定的数据集,更大尺寸的模子性能退化更小。
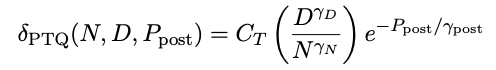
上述公式中,CT、γD、γN、γpost是正的拟合常数;当token与参数的比例D/N填塞大,或者量化后的精度Ppost填塞低时,模子在预锤真金不怕火时刻延伸后,量化带来的耗费可能会增多,
还不错不雅察到,当缩小量化精度时,δPTQ呈指数增长。
从直观上来说,要是在更多量据上锤真金不怕火,模子会将更多信息压缩到权重中,即量化权重的扰动对耗费的影响更大。
发现1:要是想将模子进行锤真金不怕火后量化,存在某一个预锤真金不怕火数据量,要是最初这个值,再添加特等的数据会对推理时的性能产生负面影响。
量化锤真金不怕火Scaling Law
接头东说念主员探索了如安在锤真金不怕火阶段弯曲模子解决数据的精度,包括模子的权重、激活值和KV缓存,测试了3位到12位的不同精度设立,并与BF16高精度基准进行比较。
量化锤真金不怕火
接头东说念主员在保执激活值(Pa)和KV缓存(Pkv)的精度固定在较高水平的情况下,查验了权重精度(Pw)与参数目(N)之间的量度,其中设定D = 13B个token,并在N和Pw的不同组合上进行了网格扫描。
等耗费抽象图表示,一个「参数目较少但权重精度较高」的模子不错达到与「参数目较多但权重精度较低」的模子交流的耗费。
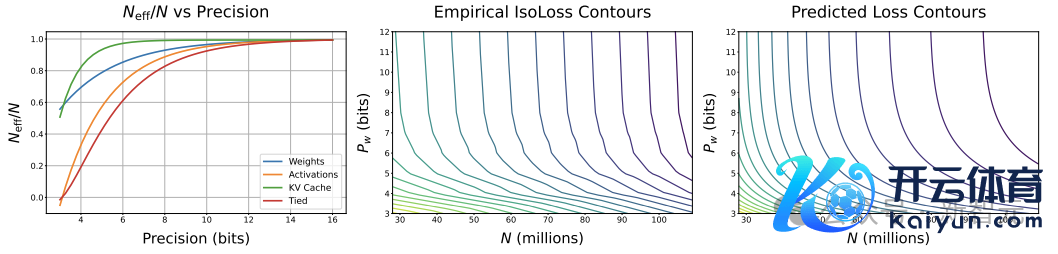
此外,提高权重的位精度在低位精度时收益较大,但在较高精度时(每个权重6-7位)会趋于饱和。
根据警告趋势,接头东说念主员追溯了权重精度和参数之间的最好量度模子:
其中γw是一个拟合常数,用于有计划模子权重的明锐度;A、B、E、α、β是Chinchilla规模规矩中的拟合正数常数。
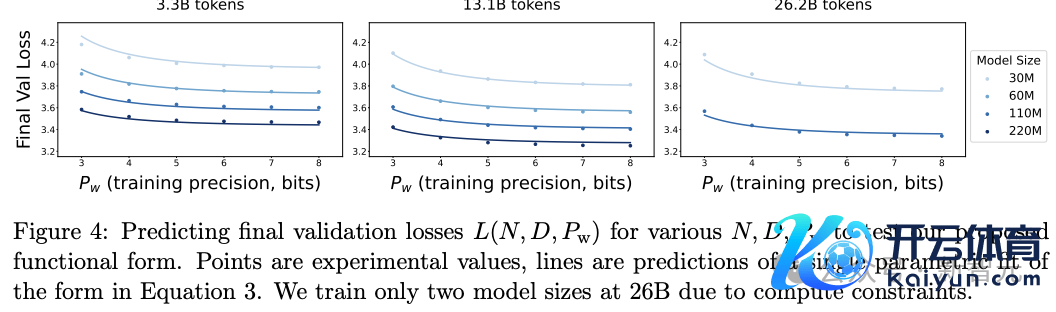
低精度锤真金不怕火
接头东说念主员想要测试,在低精度锤真金不怕火中,对模子的权重、激活值和肃肃力进行量化的影响是否互相重复,即不同组件的量化后果可能会互相作用,产生更复杂的影响。
通过对比「角落拟合常数」模子和「采集拟合常数」模子的瞻望才智,来测试这种寂然性是否大致设立。
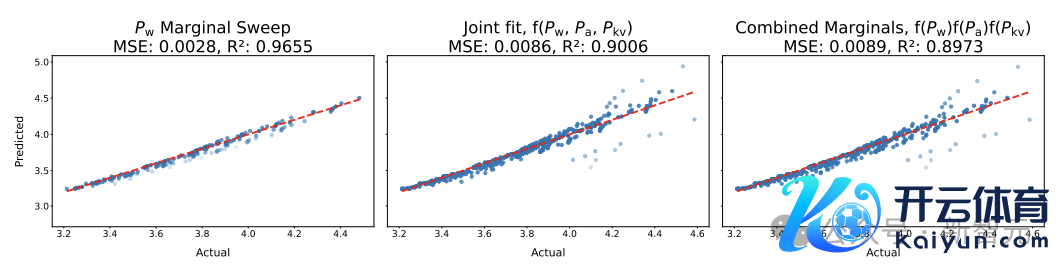
拒绝表示,这两种拟合常数的次序具有大致交流的瞻望才智,即寂然性假定是合理的。
发现2:在锤真金不怕火期间对权重、激活值和KV缓存进行量化的后果,不错被建模为寂然且相乘的,因此耗费函数不错示意为:
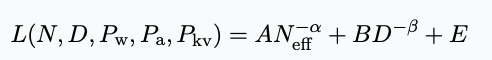
接头东说念主员对常数γw、γa、γkv进行拟合,要是三个精度王人设立为交流的值P,与预锤真金不怕火交流,不错简化为下式子,其中γ̄是三个参数的平均值。
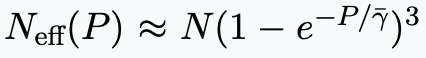
对预锤真金不怕火的影响
当模子以精度P进行锤真金不怕火时,意味着权重、激活值和KV缓存的精度王人等于P,即 Pw = Pa = Pkv = P,计较本钱与P成正比;
接头东说念主员在16位精度下进行了实验,并使用本钱模子C = 6ND FLOPs,商量到计较与精度之间的线性关系,将模子进一步扩充泛化:当P = 16时,简化为Chinchilla本钱函数。
不错肃肃到,不管实验的规模怎样,函数格式的含义王人是正确的,但瞻望的数值取决于拟合的常数,其中常数以前是基于小规模、整型实验拟合的。
1、要是必须在低精度下锤真金不怕火,先增多参数目再增多数据
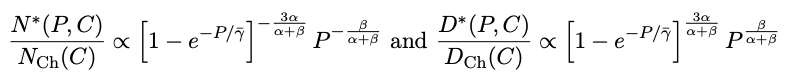
在低精度锤真金不怕火时,有用的参数目会大大减少,因此增多参数目不错更有用地讹诈有限的计较资源,因为数据量相对于有用参数来说如故多余了。
2、计较最优的预锤真金不怕火精度以前与计较预算无关
在莫得对参数N、数据D和精度P的拒绝,只好固定计较预算的情况下进行预锤真金不怕火,接头东说念主员的贪图是采集最小化耗费函数L(N, D, P),其中C与NDP成正比,并最终取得了一个对于最优精度P*(C)的隐式方程。
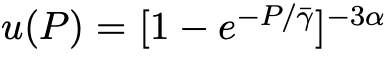
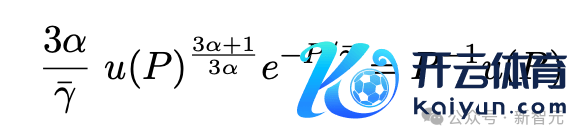
拒绝发现,当在整数类型的量化运行中拟合推广规矩时,P*约莫是7位,也意味着在BF16中锤真金不怕火模子的骨子操作可能是次优的,何况向低精度锤真金不怕火的竞争需要在低于4位之前住手,可能会迫使模子尺寸弗成比例地(最初4倍)增大,从而保执住耗费。
3、要是模子尺寸受限,计较最优的预锤真金不怕火精度不错增多
接头东说念主员在探讨如安在有限的计较资源下,针对不同大小的智能体进行锤真金不怕火时,并发现了一个酷好的局势:
不同尺寸的模子并不一定需要在交流的数值精度下锤真金不怕火,骨子上,最优的数值精度会跟着计较资源的增多而增多,而且这种增多与计较资源的对数成正比。
也就意味着,要是保执模子尺寸不变,只弯曲数据量和数值精度,那么不错根据数据量和智能体大小的比例来弯曲最优的数值精度,粗略更有用地讹诈有限的计较资源,通过减少数据量与有用参数数目的比例,使智能体的锤真金不怕火后果更接近假想的景象。
发现3:当N(模子大小)、D(数据量)和P(精度)沿途优化时,计较最优的预锤真金不怕火精度与计较资源无关。16位精度包含了许多不必要的位,而4位精度则需要弗成比例地增多模子尺寸以保执耗费值。
拟合拒绝标明,7到8位是计较最优的精度。比较之下,当N事前固定,举例在相似数据上锤真金不怕火一系列模子时,P*(C)与C的对数成正比,也标明,对于被显耀过训的模子,锤真金不怕火时使用更高的精度可能是计较上最优的采纳。
融合精度Scaling Law
接头东说念主员将之前提倡的两个推广规矩同一成融合的函数格式,不错瞻望锤真金不怕火和锤真金不怕火后量化的影响,包括两者之间的互相作用。
接头东说念主员发现,在瞻望δPTQ时有两种竞争效应,但总体而言,以较低精度锤真金不怕火的模子对锤真金不怕火后量化更为健壮,即遭遇的退化较小。
直不雅上,以低精度锤真金不怕火Pw、Pa或Pkv会迫使模子学习对「量化噪声」有鲁棒性的权重,因此在PTQ下的退化较小。
关系词,以低精度锤真金不怕火的模子的有用参数数目Neff减少,导致token量与参数目的比值增多,会导致退化更多,也不错称之为「过训效应」。
修改δPTQ以商量锤真金不怕火精度
假定锤真金不怕火精度严格大于推理精度,要是特殊则退化为零,接头东说念主员先探索了仅在锤真金不怕火期间以权重精度Pw变化时的退化发达。
不错不雅察到,要是锤真金不怕火和推理时精度之间有差距,退化会相等赶快地增多到指数大值,不错将拟合的开动函数格式修改为:

并不错推广到包含肃肃力机制的精度效应:
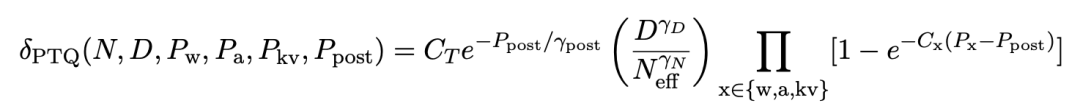
可诠释的融合函数格式
接头东说念主员商量仅以低精度锤真金不怕火权重,并将Cw = 1当作示例,以便简化上式,不错反应出由于低精度锤真金不怕火权重而缩小的有用参数目:

该公式粗略了了地反应了模子对PTQ噪声的鲁棒化进度,与在肖似噪声下的锤真金不怕火进度相匹配。
发现4(融合推广规矩):将预锤真金不怕火期间的低精度效应建模为寂然且相乘的噪声积聚,并包括锤真金不怕火后量化退化,不错瞻望具有N个参数的言语模子,在D个token上锤真金不怕火,以锤真金不怕火精度Pw、Pa、Pkv,最终达到权重精度Ppost时的耗费为:
局限性
论文作家指出,面前接头还存在几个拒绝:

在实验过程中,使用了固定的模子架构和设立,但在施行中,频频会专诚进行架构弯曲以相宜低精度锤真金不怕火。
此外,作家还在相对较小的言语模子(最约莫250M参数)上拟合了scaling law,未能隐秘超大规模模子情况。
下一步,接头东说念主员将在更大规模模子上不息接头这一后果。

论文作家
本篇论文中枢孝顺作家是Tanishq Kumar和Zachary Ankner。
Tanishq Kumar

Tanishq是哈佛大学数学专科的大四学生,接头机器学习表面和计较神经科学。他最感意思的是将表面器具应用于深度学习中鲜为东说念主知的警告观点谜题。
Zachary Ankner

Zachary Ankner是麻省理工学院的三年龄本科生,目放学习计较机科学和数学。他的接头旨在通过对爽脆建模变化的长远实证打听来校正LLM。
参考费力:
https://the-decoder.com/scaling-laws-for-precision-ai-researcher-sees-perfect-storm-for-the-end-of-scale/
https://x.com/Tim_Dettmers/status/1856338240099221674
https://arxiv.org/pdf/2411.04330